5. Better Action Space
Date: 2026-02-28 · Type: Action Space Redesign
Table of Contents
Motivation
The action space is the most fundamental interface between the agent and the environment — every policy gradient, every reward signal, every learned behaviour is expressed through it. Yet our current action table is a pile of ad hoc fixes. It started as a patch for the “B-stuck” bug (holding B caused the rifle to fire once and never again), which was solved by releasing B on the last skip frame. Each subsequent decision — always fire, 4 frames per action, release only on frame 4 — was a quick workaround, not a principled choice.
The action space deserves a careful, evidence-based redesign before we invest further training compute.
Human Play Analysis
To design a better table from evidence, we recorded 55 human gameplay sessions (11 wins, 44 losses, 288,757 frames total) and extracted two key signals: what buttons are pressed, and for how long.
What humans press
Fire (B) is active on only 29.4% of frames. Most of the time players are moving, dodging, or waiting — not shooting.
| Button | Press rate |
|---|---|
| RIGHT | 55.8% |
| DOWN | 13.6% |
| A (jump) | 8.4% |
| B (fire) | 29.4% |
| LEFT | 4.6% |
| UP | 5.5% |
The most frequent button combinations, ranked by observed frequency, give us a natural vocabulary for the new action table:
| Combination | Human freq |
|---|---|
| RIGHT | 31.6% |
| NOOP | 17.1% |
| B+RIGHT | 15.6% |
| DOWN | 7.4% |
| RIGHT+A | 6.1% |
| B+DOWN | 5.6% |
| B only | 5.2% |
| LEFT | 3.2% |
How long humans hold each input
The median button-combo hold duration from the traces is ~7 frames — nearly double the current skip=4 window. With skip=4 the agent makes decisions at ~15 Hz, far faster than the natural human rhythm of ~8 Hz. The game also imposes hard commitment windows that make sub-8-frame decisions meaningless: the bullet cooldown is ~8–10 frames, the walk animation cycle is ~8 frames, and a jump arc commits the player for ~30 frames. All of this evidence suggests a longer skip value is warranted — we use skip=8 as a reasonable starting point.
Redesign
The evidence points to two independent fixes: the action vocabulary and the frame duration.
Fix 1 — Action vocabulary
We replace the 8 always-fire actions with the top-7 human-frequency combinations (ranked by observed frequency, dropping NOOP which wastes rollout budget in search and is implicitly represented by any stationary state):
| ID | Action | Buttons | Human freq |
|---|---|---|---|
| 0 | Right | RIGHT | 31.6% |
| 1 | Right+Fire | B+RIGHT | 15.6% |
| 2 | Down | DOWN | 7.4% |
| 3 | Right+Jump | RIGHT+A | 6.1% |
| 4 | Down+Fire | B+DOWN | 5.6% |
| 5 | Fire | B | 5.2% |
| 6 | Left | LEFT | 3.2% |
The agent now chooses when to fire rather than being forced to fire on every action. The B-release frame is kept on action 1 (RF), 4 (DF), and 5 (F) to maintain rapid-fire capability.
Fix 2 — Frame duration (skip 4 → 8)
From the human traces the median button-hold duration is ~7 frames. With skip=4 the agent makes decisions at ~15 Hz — nearly double the natural human rate of ~8 Hz. More importantly, the game itself imposes hard commitment windows that make sub-8-frame decisions useless:
- Jump arc: once airborne (~30 frames), horizontal direction is largely committed.
- Bullet cooldown: the game allows at most 3 bullets on screen; a new shot cannot spawn until an old one clears, roughly every 8–10 frames at close range.
- Walk animation cycle: ~8 frames per step — actions shorter than one cycle have no visible effect on movement.
We set skip=8, matching the bullet cooldown and animation cycle while halving the decision rate to be consistent with human play rhythm.
Monte Carlo Search Validation
Before committing to a full PPO training run, we validated the new design using the Monte Carlo playfun search as a benchmark. Each configuration was given an equal rollout action budget; the metric is how much progress the search makes before the budget is exhausted.
Navigation (max xscroll from Level 1 start)
Results averaged over 5 independent trials, equal rollout action budget per config.
| Config | xscroll (mean ± std) |
|---|---|
| Old table, skip=4 | 708.8 ± 332.5 |
| New table, skip=4 | 1130.0 ± 41.4 |
| Old table, skip=8 | 1235.2 ± 167.8 |
| New table, skip=8 | 2059.4 ± 43.9 |
With skip=4 the old table makes erratic progress (high variance, 332 std) — rollouts are short and many end in early death, constantly forcing rewinds. Skip=8 gives each rollout enough time to develop, and the new vocabulary’s directional actions (R, RJ) give the search a cleaner signal to commit to. The two fixes compound: the new table alone adds ~59% xscroll at skip=4, skip=8 alone adds ~74% over the old table, and together they reach 2059 xscroll — nearly 3× the old baseline.
Training Results
We ran two PPO training runs with the new action table and skip=8, both using multi-state training across the full level and boss arena — one with the dense boss hit reward enabled, one without.
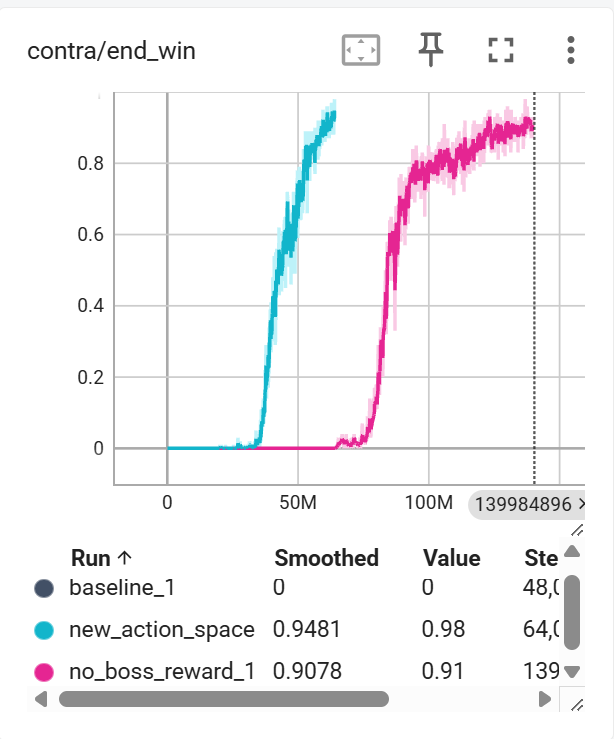
The agent guided by the boss hit reward reaches 80% win rate at 64M steps. The agent without it takes until 140M steps to reach the same win rate. Both ultimately converge to the same performance level — the dense reward signal does not change what the policy learns, only how quickly it gets there.
This tells us the boss hit reward is a convergence accelerator, not a crutch. PPO with the sparse score and win signals alone eventually discovers the correct strategy, but needs roughly 2× the compute budget to do so. The RAM-derived hit counters simply give the agent earlier, denser feedback on a behaviour — sustained fire at the boss — that the game’s native score signal rewards too infrequently to learn from efficiently.

The practical implication for Level 2 is clear: identifying the equivalent boss HP counters in RAM is worth the upfront effort, as it halves the training budget needed to achieve the same win rate.